翻译电子书教程02:使用Python整理文本

上回 我们讲到,想自动翻译外文电子书的第一步,是把书转换为htmlz的格式,也就是html文档的压缩包,在命令行使用unzip解压,可以得到图片文件夹、装饰文件,以及html文本文档
这回,目标是从html文档提取纯文本,传送到搜索引擎翻译。最简单的方式是:Ctrl + A 全选html文字,ctrl + C粘贴到txt文档。
但这样有两个问题:
1、如果html文档较大容易死机; 2、无法自动化,必须人工处理。
为解决这些问题,我们选用人生苦短缓解器的Python处理,开始之前假设你已装好了Python环境。
我们以PyCharm环境举例,如果你装其他任何编译器都行,效果一样,设置可以跳过中间的配置步骤。
完成准备工作后我们开始:
打开命令行,创建Python脚本
命令行是我们对操作系统发号施令的地方,多数程序员们喜欢命令行,因为所有操作不用鼠标,而且可以批量自动化处理多行命令。
脚本英文是script,原义指:手稿,以前指戏剧或电影的底稿。戏剧的script是控制人的,而计算机上的script则是控制计算机的。区别于那些二进制文件(如windows上的.exe文件),脚本仅指可以直接运行的文本文件。
打开上回 已经做的好文件夹:

右下角点击右键,在弹出菜单选择在终端打开:
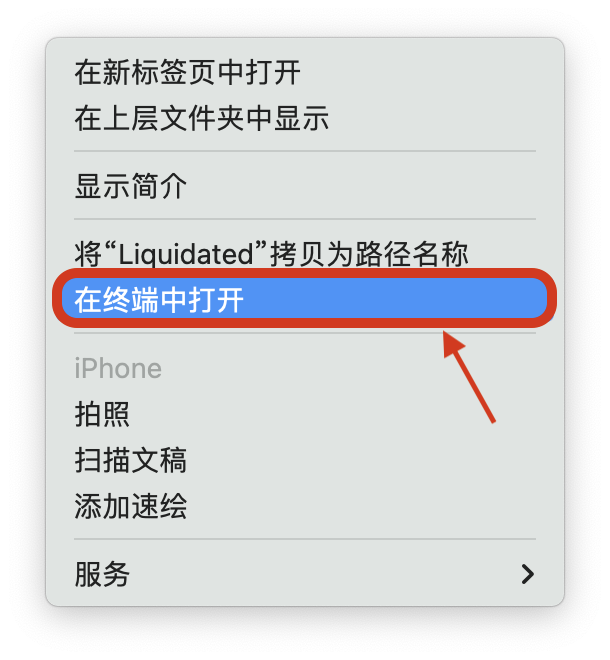
在命令行输入echo > proc_html.py:

于是,在这个文件夹内出现一个名为proc_html的Python脚本文件:

配置Python环境路径
右键proc_html.py,以你的Python编译器打开,这里以PyCharm举例:左侧是目录区,右侧是脚本编辑区。

初次使用,需要在右下角Configure a Python interpreter设置环境目录,如果不慎误点取消,还可以点击右下角Event Log继续选择:

在弹出的菜单中选择:Interpreter Settings:
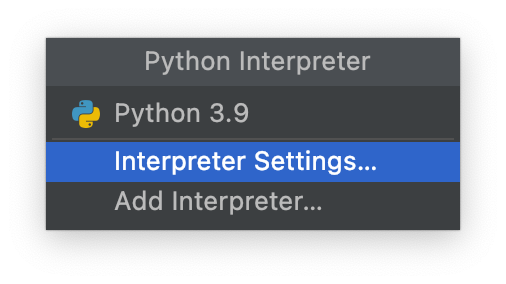
在弹出的菜单中选择Project Structure,删除原路径,

再添加新路径:/Users/tangqiang/doraemonj/docs/calibre/Karen_Ho/Liquidated,点击右下角OK:

新路径可以在原路径文件夹框右下角点选拷贝为路径名称复制得到:

完成后点击PyCharm环境下方Python Console,若无红字报错,则配置成功:

安装BeautifulSoup
点击PyCharm环境下方Terminal按钮,在提示符后输入:pip3 install BeautifulSoup4

如果系统提示DEPRECATION而无法安装,就使用pip install --upgrade pip命令在Terminal中更新下。那么,可以继续pip3 install BeautifulSoup4命令安装BeautifulSoup4。
BeautifulSoup4(简称bs4)包是处理html文档的超级工具,有了它相当于你属下凭空多了1000人的文本处理团队,随时等你下命令。
输入代码
1import bs4
2
3# 设定:路径、html文件名和最终输出的txt文件名
4path = r"/Users/tangqiang/doraemonj/docs/calibre/Karen_Ho/Liquidated/" #注意路径名最后有一个斜杠
5html_file = "index.html"
6txt_file = "en.txt"
7
8# 读取index.html文件
9with open(path + html_file, "r") as f:
10 txt = f.readlines() # 以段落形式,每段一行
11
12# 逐段处理带有html标签的文本,写入txt文件,准备上传deepL翻译
13for el in txt:
14 # 导入带有html标签的文本,交由bs4包处理
15 soup = bs4.BeautifulSoup(el, features='lxml')
16
17 # 去除html文件中的span标签
18 for span in soup.find_all("span"):
19 span.unwrap()
20
21 # 提取标签中的纯文本,逐段写入txt文件
22 for para in soup.strings:
23 with open(path + txt_file, "a") as f:
24 f.write(para)
25 f.write("\n")
26
运行代码:PyCharm环境中全选代码,mac系统用户按快捷键:ctrl + option + E
即在指定文件夹中出现txt文件,可直接上传deepL翻译:

附:
1、Python脚本文件:proc_html.py
2、电子书纯英文文本:en.txt